(WIP) MAIAP: Multimodal AI-based Interface for Audiovisual Performance
Date: July 2024-
Categories: AI Art, Audiovisual Interface, Audiovisual Performance, Generative
Categories: AI Art, Audiovisual Interface, Audiovisual Performance, Generative
I have been working on designing a novel interface for utilizing image and sound AI models in audiovisual performance. As an early experiment, I created a prototype that generates images and sounds with pre-trained models in response to real-time webcam and mic input. The prototype was demonstrated in one of Exit Points' performances on August 30, 2024 at Arraymusic, which was organized by Michael Palumbo.
The prototype uses SpecVQGAN for sound generation and StreamDiffusion with Stable Diffusion XL Turbo for image generation, both with modifications.
Exit Points #52 Ensemble 2 Performance Footage
My Sound Generated
Exit Points #52 Switchemups Session (Visualization Only)
Credit for the performance
- MAYSUN: Percussion, Electronics
- Danika Lorén: Opera
- Emmanuel Lacopo: Electric Guitar
- Michael Palumbo: Modular Synth
- Sihwa Park: AI-generated Sound, Visualization
- Video and audio recordings for the first video were provided courtesy of Arraymusic and Michael Palumbo.
This project is undertaken thanks in part to funding from the Connected Minds Program, supported by Canada First Research Excellence Fund, Grant #CFREF-2022-00010.
Diffusion TV
Date: May 2025
Categories: AI Art, Audiovisual Installation, Generative
Categories: AI Art, Audiovisual Installation, Generative
Diffusion TV is an experimental and interactive interface that invites audiences to explore the hidden processes of AI through a nostalgic CRT TV interface, allowing them to engage directly with diffusion models, the technology behind today’s most sophisticated AI-generated images and sounds.
Inspired by Nam June Paik’s Egg Grows (1984–1989), which depicts the illusion of an egg growing through a series of progressively larger CRT TVs, Diffusion TV uses the old CRT TV to reveal the hidden process of AI denoising, transforming the complexity of AI diffusion models into a tangible, interactive experience. The work allows viewers to directly engage with the transformative process of turning chaotic data into recognizable images and sounds by adjusting the TV’s antenna and knobs, fostering a deeper connection between human interaction and technological transformation.
By turning the knob, viewers can switch between three channels: Past, Present, and Future. The Past channel focuses on extinct animals to reflect on what has already disappeared, evoking a sense of loss and remembrance. The Present highlights the fragility of endangered species, offering a moment of reflection on the current environmental crisis. The Future channel displays speculative animals imagined with AI, encouraging contemplation about where humanity and technology are headed. Each channel presents audiovisual content generated by AI models such as Stable Diffusion XL and Stable Audio Open, dynamically adapting to the viewer’s adjustments.
By adjusting the antenna, the audience gradually brings the animals into clearer focus, metaphorically remembering, preserving, or exploring their existence. Once the clearest image and sound of an animal are revealed, the process resets after a few seconds, returning to a noisy and unclear depiction of another animal, keeping the experience dynamic and ever-evolving. Like television programming, Diffusion TV continuously renews its content by regenerating the images and sounds of the animals at regular intervals.
Diffusion TV explores how technology can shape our understanding of the natural world. Using the CRT TV, once an emblem of cutting-edge innovation but now a metaphor for obsolescence, the work mirrors the fragility of endangered species and asks what is preserved and what is lost in the pursuit of technological advancement. Through a more experiential, interactive understanding of AI’s inner workings, Diffusion TV encourages audiences to contemplate the interconnected relationships between humanity, technology, and nature.
This project was undertaken thanks in part to funding from the Connected Minds Program, supported by Canada First Research Excellence Fund, Grant #CFREF-2022-00010.
Diffusion TV at ISEA 2025, Hangaram Design Museum, Seoul, Korea
Diffusion TV was exhibited at ISEA 2025 as one of 39 juried artworks selected from 355 submissions.



Diffusion TV at CVPR AI Art Gallery 2025, Music City Center, Nashville, USA
Diffusion TV was featured in the CVPR AI Art Online Gallery 2025 as one of the shortlisted works, and was displayed on site as a loop video at the CVPR conference.



Diffusion TV at the Connected Minds Conference 2025 Arts Reception


Diffusion TV as an Honoree for the AI Creative Awards 2025
Diffusion TV has been chosen as an honoree for the AI Creative Futures Awards (AICA) 2025. AICA is a Japan-based award that celebrates AI-driven creative works, offering new perspectives on the future of creativity. The award ceremony took place in Tokyo on December 17, 2025 and was live-streamed on YouTube. Learn more at https://aica-awards.com/


Related Exhibitions
Oct 2025, “Diffusion TV” at the Connected Minds Conference 2025 Arts Reception (Invited), Sandra Faire and Ivan Fecan Theatre, York University
Jun 2025, “Diffusion TV” at the IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR) AI Art Gallery 2025 (On-site display and online, shortlisted)
May 2025, “Diffusion TV” at the International Symposium on Electronic/Emerging Art (ISEA) 2025, Hangaram Design Museum, Seoul, Korea
YouTube Mirror
Date: May 2022
Categories: AI Art, Data Art, Audiovisual Installation, Generative
Categories: AI Art, Data Art, Audiovisual Installation, Generative
YouTube Mirror is an interactive, audiovisual AI installation that generates images and sounds in response to the images of the audience captured through a camera in real time, in the form of an interactive mirror. YouTube Mirror uses a cross-modal generative machine model that was trained in an unsupervised way to learn the association between images and sounds obtained from the YouTube videos I watched.
YouTube Mirror employs a concept of interactive mirror in digital media arts, as a way to represent how machine vision perceives the world. Since the machine represents the world solely based on its learned audio-visual relationship, the audience can see themselves through the lens of the machine’s vision with the machine-generated images and sounds.
YouTube Mirror is an artistic attempt to simulate my unconscious, implicit understanding of audio-visual relationships that can be found in and limited by the videos. YouTube Mirror also attempts to represent the possibility of the machine’s bias inherent in a small-size video dataset which is possibly affected by video recommendation algorithms on YouTube, in an abstract and artistic way.
YouTube Mirror at NIME 2023, Mexico City, Mexico
This version of the installation accompanied a video grid that loops 300 YouTube clips randomly selected among the whole 6,091 video data in order to show what data was used for training the model.
YouTube Mirror at AIMC 2023, Brighton, United Kingdom



Related Publication
Sihwa Park, “YouTube Mirror: An Interactive Audiovisual Installation based on Cross-Modal Generative Modeling”, In Proceedings of the International Conference on AI and Musical Creativity (AIMC), Brighton, United Kingdom, 2023
Related Exhibitions
Jun 2024, “YouTube Mirror” at the IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR) AI Art Gallery 2024 (Online)
Aug 2023, “YouTube Mirror” at the International Conference on AI and Musical Creativity (AIMC), Attenborough Centre for the Creative Arts, Brighton, United Kingdom
May 2023, “YouTube Mirror” at the International Conference on New Interfaces for Musical Expression (NIME), Centro de Cultura Digital, Mexico City, Mexico
May 2022, “YouTube Mirror” at the MAT 2023 End of Year Show: SYMADES, California NanoSystems Institute, UCSB, Santa Barbara, USA
Uncertain Facing
Date: Jun 2020
Categories: AI Art, Data Art, Audiovisual Installation, Generative
Categories: AI Art, Data Art, Audiovisual Installation, Generative
Uncertain Facing is a data-driven, interactive audiovisual installation that aims to represent the uncertainty of data points of which their positions in 3D space are estimated by machine learning techniques. It also tries to raise concerns about the possibility of the unintended use of machine learning with synthetic/fake data.
As a data-driven audiovisual piece, Uncertain Facing consists of three major components: 1) face data including synthetic images of faces, generated by StyleGAN2, a generative adversarial network (GAN) for generating portraits of fake human faces, and their face embeddings obtained from FaceNet, a deep neural network trained for finding 128-dimensional feature vectors from face images, 2) t-SNE (t-distributed Stochastic Neighbor Embedding), a non-linear dimensionality reduction technique for the visualization of high-dimensional datasets, and 3) multimodal data representation based on metaball rendering, an implicit surface modeling technique in computer graphics, and granular sound synthesis
Uncertain Facing visualizes the real-time clustering of fake faces in 3D space through t-SNE with face embeddings of the faces. This clustering reveals which faces are similar to each other by deducing a 3-dimensional map from 128 dimensions with an assumption based on a probability distribution over data points. However, unlike the original purpose of t-SNE that is meant to be used in an objective data exploration in machine learning, it represents data points as metaballs to reflect the uncertain and probabilistic nature of data locations the algorithm yields. Face images are mapped to surfaces of metaballs as textures, and if more than two data points are getting closer, their faces begin to merge, creating a fragmented, combined face as a means of an abstract, probabilistic representation of data as opposed to exactness that we expect from the use of scientific visualizations. Uncertain Facing also reflects an error value, which t-SNE measures at each iteration between a distribution in original high dimensions and a deduced low-dimensional distribution, as the jittery motion of data points.
Along with the t-SNE and metaball-based visualization, Uncertain Facing sonifies the change of the overall data distribution in 3D space based on a granular sound synthesis technique. The data space is divided into eight subspaces and the locations of data points in the subspaces are tracked during the t-SNE operation. The density of data points in each subspace contributes to parameters of granular synthesis, for example, grain density. The error values also are used in determining the frequency range and duration of sound grains to represent the uncertainty of data in sound.
As an interactive installation, Uncertain Facing allows the audience to explore the data in detail or their overall structure through a web-based UI on iPad. Moreover, the audience can take a picture of their face and send it to the data space to see its relationship with the data. Given the new face image, Uncertain Facing re-starts t-SNE after obtaining face embeddings of the audience’s face image in real time. While the real audience face is being mixed, merged with the fake faces in 3D space, Uncertain Facing also shows the top nine similar faces on the UI. Here, it tries to imply an aspect that machine learning could be misused in an unintended way as FaceNet does not distinguish between real and fake faces.


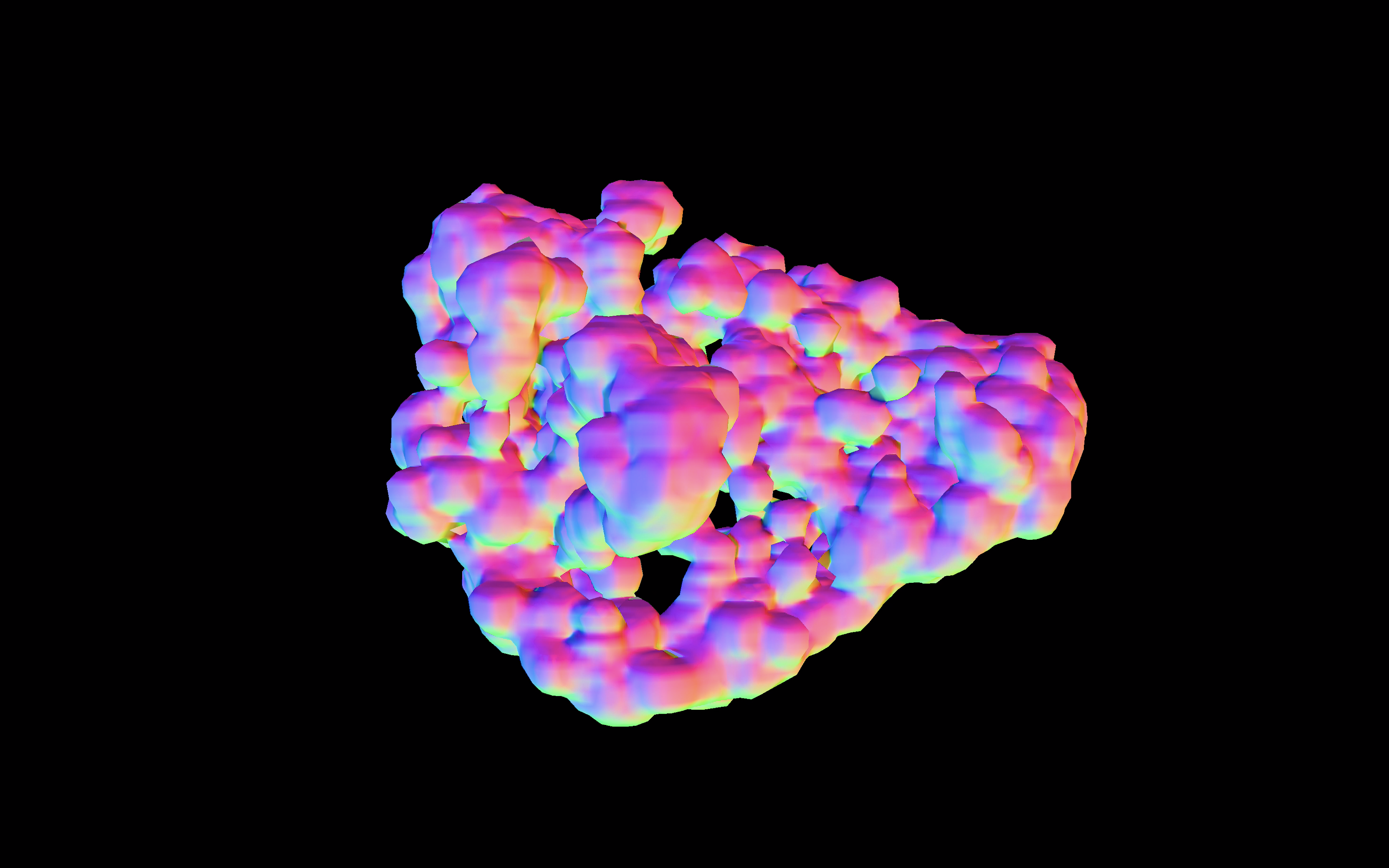



Interactive Installation at Ars Electronica Festival 2020





Group exhibition “The Wild State”, Kunstuniversität Linz 2020, Photo: Su-Mara Kainz
Related Exhibitions
Nov 2021, “Uncertain Facing” at the Special Exhibition of AIIF 2021 Advanced Imaging & Artificial Intelligence (Online, invited)
Dec 2020, “Uncertain Facing” at the NeurIPS 2020 Workshop on Machine Learning for Creativity and Design (Online; displayed on its AI Art Gallery)
Dec 2020, “Uncertain Facing” at the SIGGRAPH Asia 2020 Art Gallery (Virtual), Daegu, Korea
Oct 2020, “Uncertain Facing” at the IEEE VIS Arts Program (VISAP) Exhibition (Online), Salt Lake City, Utah, USA [Presentation]
Sep 2020, “Uncertain Facing” at The Wilde State: Networked exhibition, Ars Electronica Festival 2020, Linz, Austria
Jun 2020, “Uncertain Facing” at the MAT 2020 End of Year Show: Bricolage (Online), UCSB, Santa Barbara, USA
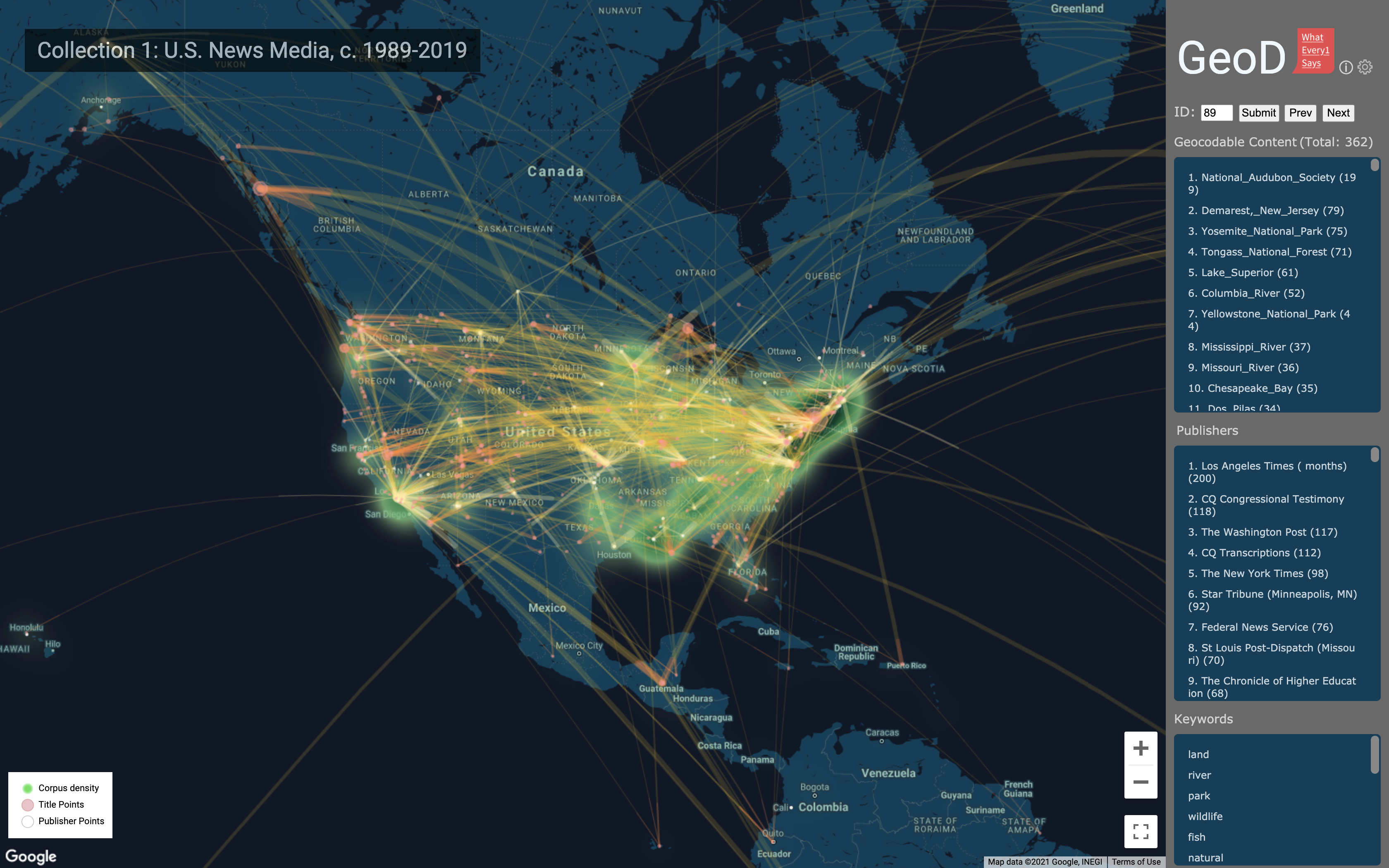
GeoD
A Geographical Visualization of Topic Models with WikificationDate: Jul 2019 - Jul 2020
Categories: Data Visualization, UI/UX Design
Categories: Data Visualization, UI/UX Design
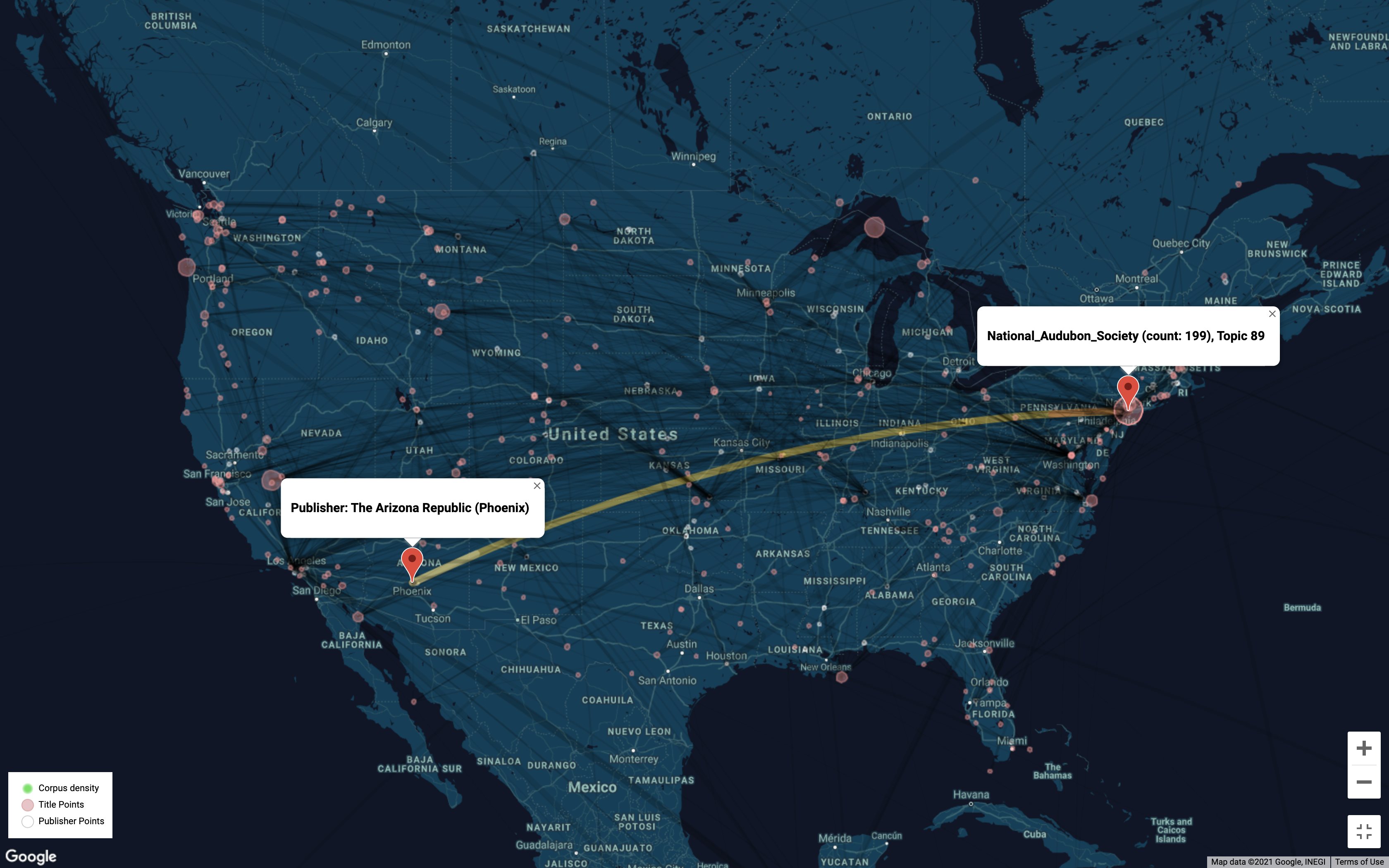
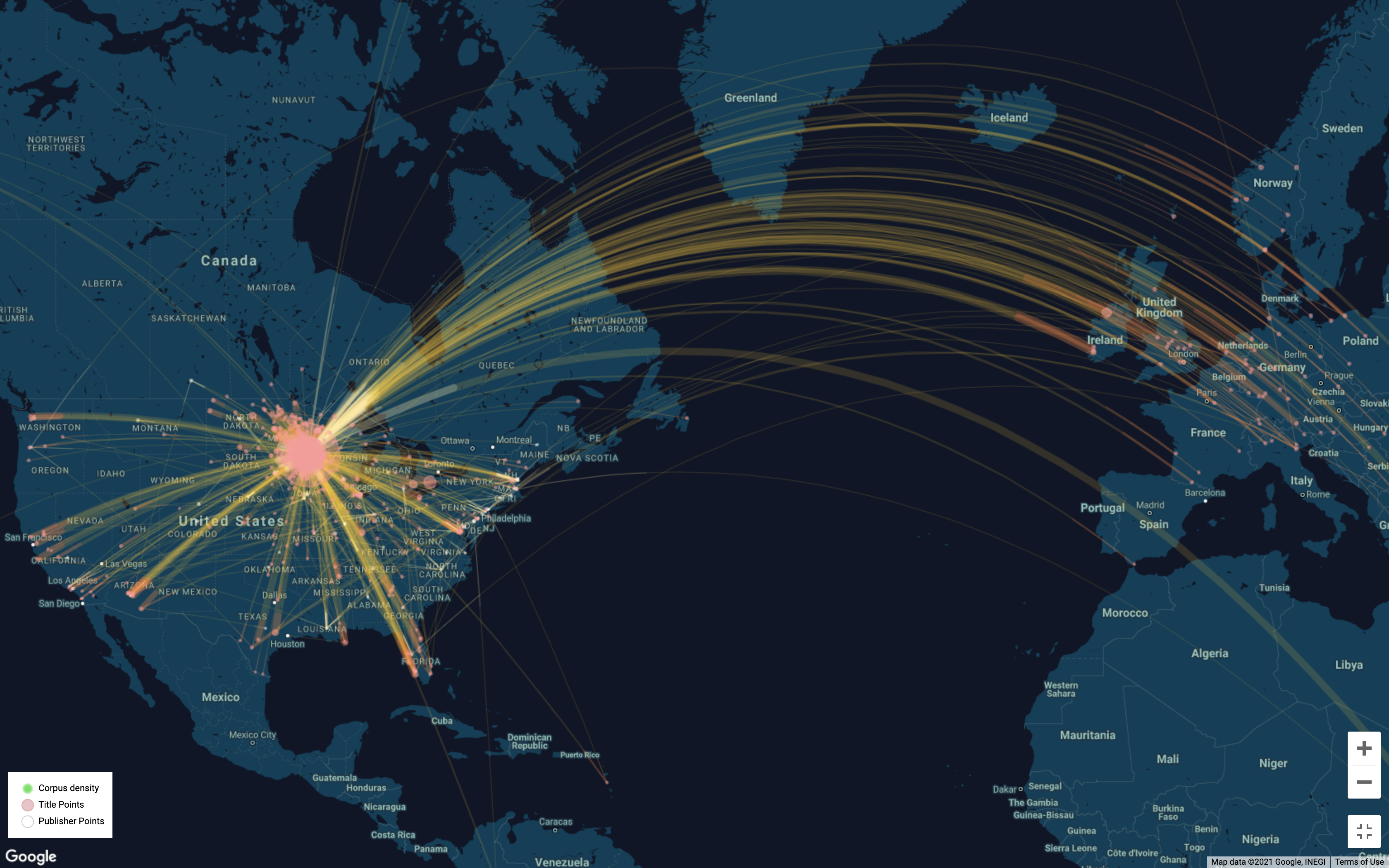
GeoD visualizes geographical information (locations and entities with geocoded information) contained in topic models. It can be used to analyze locations discussed in the whole corpus underlying a whole model or in a specific topic.
The geocoded information that GeoD maps is gathered from the corpus for a topic model first through a “wikification” process (using the Illinois Wikifier; see L. Ratinov et al., 2011) that confirms the recognition of named entities by checking for correspondence to locations, organizations, etc., for which there are articles in Wikipedia, and secondly through collecting latitude/longitude information for the data. (However, not all possible named entities can be recognized and geocoded as locations in this way.)
Please refer to the related article, Cultural life: Theory and empirical testing (Dan C.Baciu, 2020), for detail.
GeoD was created by WE1S Interpretation Lab, which is part of the WhatEvery1Says (WE1S) project where I worked as a Research Assistant with the role of Data Visualization Specialist.
Working example
Github repo
Credits
Created by the WE1S Interpretation Lab members:
- Dan C. Baciu: data science concept, design concept, supervision
- Sihwa Park: design and development lead, data visualization, interface design
- Xindy Kang: initial visualization, interface design
Visual Coding
- White circles: publishers
- Pink circles: published news content
- Yellow lines connect publishers with the content that they published.
- Lines are tinted white towards publishers and red towards content.
- Green haze heatmap represents areas densely covered by news in this corpus.
Data
Among the WE1S data collections, the data for demonstration uses “Collection 1: U.S. News Media, c. 1989-2019”, which is the WE1S core collection of 82,324 unique articles mentioning “humanities”.
Various Views of a Topic

Topic-wise Comparison

Related Project
https://sihwapark.com/TopicBubbles